こんにちは、価格.comショッピングシステム部の山内です。
価格.comショッピングシステム部では日々の業務に対して改善を重ねてきています。
振り返ってみればすでに4年前のことですが、今まで行った改善の中でとても印象に残った事例を一つ紹介致します。
大量データの処理
大量データというと、大体どれくらいを想像されますか?
200万件くらい?
1000万件以上?
価格.comのショッピング領域では日々6億件を超える商品データを処理しています。
各モール様やショップ様から商品データをダウンロードし、1日1回以上の頻度で更新しています。
全部ではありませんが、半分以上のデータが実際に取り込まれています。
取り込んだデータは検索エンジンを通して、価格.comのトップページの上部検索ボックスから商品を検索できるようになっています。

データの調査
日々の運用の一環として、これらの商品のデータを調査することがあります。
例えば
- この商品が取り込まれていないようだけど、元データにそもそもある?
- このショップの商品の表示内容が正しくないように見えるけど、元データはどうなっている?
- 取り込んでいないデータの中で、こういう条件に当てはまるデータはどれくらいある?
などなど
取り込み済みのデータの調査はそこまで大変ではありませんが、上記のように取り込めていないデータや元データの調査依頼が多く、それに時間と労力を要していました。
元データは主にCSVファイルの形式ですが、それの調査には都度ローカル環境にツールを作っていました。
しかし、一回限りの調査のためのものも多くあって、そのまま流用することは難しく、毎回コードを書き換える必要がありました。
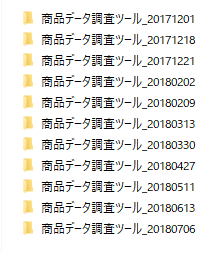
ご覧のあり様です。コピペツールの大量発生。
そして、6億件以上にもなると、ローカルでいくら並行処理を走らせても数時間はかかり、1回の調査に約半日はかかっていました。
はい、正直やってられませんでした。
取り組み
きっかけは他愛もない雑談からだったと記憶しています。
「なんか他のところがGCPを検証してるらしいね」
「うちで日々ダウンロードしてるデータファイルをBigQueryで検索したらめっちゃ調査楽になりそう」
「ほなやってみるか?」
そんな感じでGCPの検証も兼ねて試験目的で予算を取り、しっかりとした目的を持ちつつも、フットワーク軽めで改善を始めました。
作ったもの
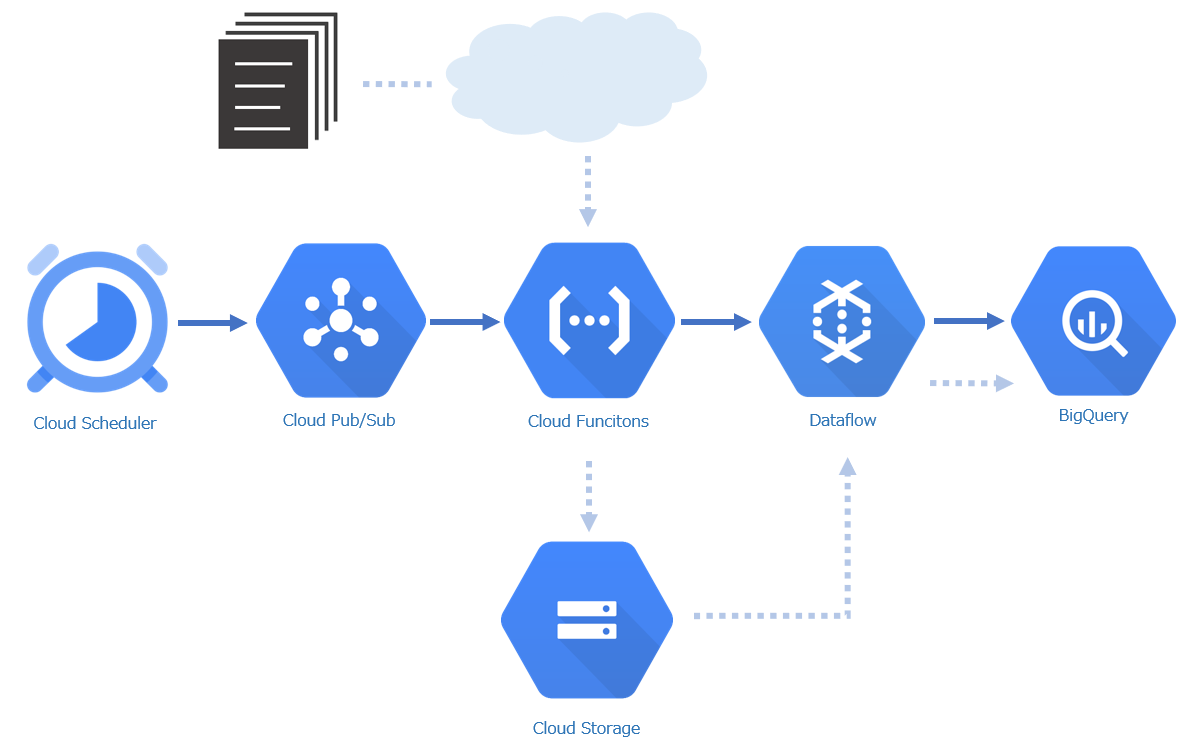
上記のサービスを組み合わせて、BigQueryにデータを取り込みました。(実装者の保科さんにちなんで、HoshinaQueryと呼んでいます。)
料理番組のようにいきなりできたように見えますが、実際はクラウドの知見がほとんどない中、半年以上かけて検証しながら作り上げたものなのでそれなりの苦労はしました。
表面的な内容ではありますが、それぞれのサービスがどういう役割を果たしていたかを簡単にご紹介します。
Cloud Scheduler
モール様、ショップ様によってファイルをダウンロードする時間が異なるため、それぞれ実際の取り込み処理と同じファイルをダウンロードできるように処理開始を時間コントロール。タスクスケジューラやcronのようなもの。Cloud Pub/Sub
処理のつなぎ役。メッセージを受け取って次の処理のインプットとして渡すもの。なぜCloud FunctionsとDataflowの間には入っていないかって?サンプルコードが直接呼んでいたので、そのままにしていました。もちろんCloud Pub/Subを通してもできるはずです。Cloud Functions
サーバレスのランタイム環境。データファイルをダウンロードし、Cloud Storageに格納する処理をここで実装しました。ツール程度の簡単な処理は全部これでいいんじゃないかと感じました。Cloud Storage
ファイル保管用のストレージです。世代管理ができますが、今回の取組においてその機能は使いませんでした。Dataflow
大量データの処理をパイプラインで定義し、並列処理で実行してくれます。これによってダウンロードしたファイルを手軽に、高速にBigQueryに入れることができました。BigQuery
言わずもがなの大量データを処理できるデータウェアハウス。保存したデータをブラウザからクエリベースで検索、分析ができます。取り込んだデータファイルを好きな条件で調査するために利用。
結果
調査がめっちゃ楽になった
- 自動で毎日データを溜めるようになったので、調査依頼があるたびにファイルをダウンロードしなくてよくなりました。
- データが常に本番のデータと同じものなので、そもそもデータあってるんだっけ?を気にしなくてもよくなりました。
- 10日分のデータを蓄えているので、過去の調査も可能になりました。
- クエリで検索できるのでツールを作る必要がなくなりました。
- とりあえず見てみる?ができるようになり、気軽に調査ができるようになりました。
調査がめっちゃ速くなった
実際発生した調査だと、どんな条件でも1回のクエリ実行が数秒で終わります。
クエリの作成時間を入れても半日かかっていた調査が、10分もかからなくなりました。
これが高速化か...いいえ、爆速化です。
でもお高いんでしょ?
さて、気になるコストですが、約45,000円/月かかっていました。
安くはない…安くはないが、運用でかかっていたコストと比べると安いです。
内訳のほとんどがBigQueryの保管料になります。BigQueryの実行コストは誤差範囲で(1回数円~数十円程度)よほど無茶に使いまくらなければ気にする必要がないレベルでした。
アドホックな検索程度の利用だと、節約する場合は保管期間を減らすのが最も効果的ですね。
その後
あれから約2~3年程HoshinaQueryを使った調査で運用をしましたが、その後、弊社の検索エンジン部分を担っている別の部署に取り込み処理を丸ごと移管することになりました。
その際により良い設計にしていただき、データを最初からGCP上に格納することになりました。
そのため、本番のファイル取り込み処理と並行していたHoshinaQueryは不要になり、2023/4についに役目を終え、現在は停止しています。
振り返ってみれば、運用の負荷の軽減という目的を果たしながらも、とてもいい経験ができたと思います。
これほど大掛かりな仕掛けはなかなか作ることは少ないですが、日々の改善は常に行っていますし、割と自由な発想でチャレンジできます。
今後も一緒に改善に取り組んでいただける方を応募しておりますので、ご興味ある方はぜひお力をお貸しください!
