ごあいさつ
初めまして。価格.com基盤システム部のSRE担当の橋本と申します。
入社当初はアプリケーション開発を担当していましたが、現在の業務は価格.comのサービスで利用している様々なサーバのミドルウェアの構築・設定・運用を中心に、基盤モジュールや開発支援ツールの開発等、多種多様で幅広くシステムに携わっています。
私が入社した当時は、Windows一辺倒な環境でしたが、昨今はLinuxを中心にOSSの導入も進めていて、WebサーバもIISだけでなくapacheやnginxも活用しています。
今回は題名に書いていますが、利用しているnginxのログ運用について、ちょっとした工夫による運用改善の実例をご紹介させて頂きます。
はじめに
まずは、Webサーバ(nginx)のログ運用について、簡単な説明と、運用での問題点について説明します。
Webサーバ(nginx)のログ運用と問題点について
価格.comは、日々の大量なリクエストを処理するため、運用では数百台のサーバでシステム運用を行っています。その膨大な数のWebサーバのアクセス状況を迅速に把握するためにはログデータの一元的な管理は必須で、価格.comではElasticsearchを活用しています。価格.comではWebサーバにある各種ログをElasticsearchに集約してログの一元管理を行っていまして、システム担当者内では『可視化環境』と呼んでいます。
『可視化環境』の全体構成は下図になります。今回はその内のnginxの部分をピックアップして説明します。
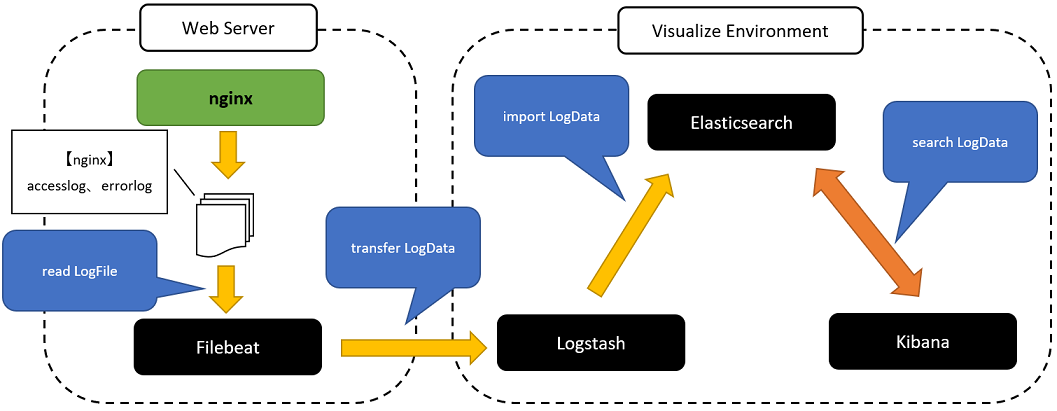
構成ですが定期的にバージョンアップの運用を行っている手前、至ってシンプルにすることを心掛けていまして、現状はElastic Stackで固めています。
nginxについては、その『可視化環境』にアクセスログとエラーログを取り込みの対象にしています。
まずFilebeatが、nginxから出力されるアクセスログやエラーログを読込(read)してLogstashに転送(transfer)。Logstashは、その受信したログデータを整形してElasticsearchに登録(import)します。システム担当者がKibanaで、そのElasticsearchに登録したログデータを必要に応じて検索(search)する、といったスタンダードな流れです。
一見何の問題が無いようにみえますが、nginxについてはエラーログを解析する際に問題点があります。
アクセスログは構造化データであるため、そのログデータのままElasticsearchに登録しても、Kibanaでの検索は簡単に出来る一方で、エラーログはnginxの仕様で『利用者側でフォーマットをカスタマイズが出来ない非構造化テキストデータである』が故、そのまま単純に検索することは出来ません。
ここで簡単ですが、nginxのエラーログについて説明いたします。
nginxのエラーログメッセージの一例を以下に記します。非構造化データは「directory index~」以降になります。
2023/05/15 23:15:12 [error] 40794#40794: *5776603194 directory index of "/usr/share/nginx/html/hoge/" is forbidden, client: 192.168.1.1, server: test.example.com, request: "GET /hoge/?test=fuga HTTP/1.1", host: "test.example.com:443", referrer: "https://demo.example.com/"
エラーログ自体は大枠のフォーマットは、
(TIMESTAMP) [(LEVEL)] (PID)#(TID): *(CID) (MESSAGE)
の形式で左から順に、タイムスタンプ(TIMESTAMP)、 重大度レベル(LEVEL)、プロセスID(PID)、スレッドID(TID)、コネクションID(CID)、メッセージ(MESSAGE)、です。nginxは様々な通信プロトコルに利用されるが故、その用途に応じたメッセージ出力であるためにメッセージが非構造化データになっています。補足で、Filebeatには、この項目で取り込むためのテンプレートが予め準備されています。(参考)
一般的に非構造化データは、定常監視、障害解析や自動化等、様々な場面で物事を困難にします。
エラーログをこのままの形式でElasticsearchに登録したとして、例えば障害発生時の初動調査であるクライアントIPアドレスを条件にKibanaの検索フィルタで検索する場面について、まず大前提として作業者がnginxのエラーログメッセージのデータ構造を理解しておかないと正しい検索は困難です。 その場合、まずスキルに依存するためにアサインする担当者が限定される傾向になり(※初学者ついてはアサインすら出来ない)、仮にデータ構造を理解していても、データ抽出・分析する時間を要する事になりがちで、問題特定において時間が掛かる、、、といった悪循環が生じてしまいます。
nginxエラーログ運用の改善
そうは言っても、エラーログは問題を特定するために重要な情報源であるため、定常時から作業者のスキルに極力依存することなく誰でも検索できる状況にしておきたい、という考えのもと、エラーログを構造化データに変換してElasticsearchに登録する仕組みを検討しました。そして、LogstashのGrok filter pluginを問題解決のその手段として活用することで考えました。Grok filter pluginは、エラーログのメッセージのような非構造化データを一般的な正規表現と予め準備されているテンプレート的な正規表現を組み合わでマッチした内容から構造化データに変換するプラグインで、複雑になりがちな正規表現をシンプルな定義で実行できることがメリットです。
では、実際の作業ステップを下記にまとめますと、
- nginxのエラーログを解析して、メッセージのパターンを洗い出す。
- 洗い出したメッセージパターンから、Grokに適用する正規表現を定義する。
- LogstashにGrokの正規表現を適用してエラーログをElasticsearchに登録してKibanaで検索する。
になります。
まず、エラーログの解析ですが、概ね2~3カ月ほど蓄積したデータとGrokで適用した正規表現を全量マッチングを行い動作検証しました。その正規表現をLogstashに適用して最終的に、下図のような検索が出来るようになりました。(※実運用と一部異なる箇所があります。)
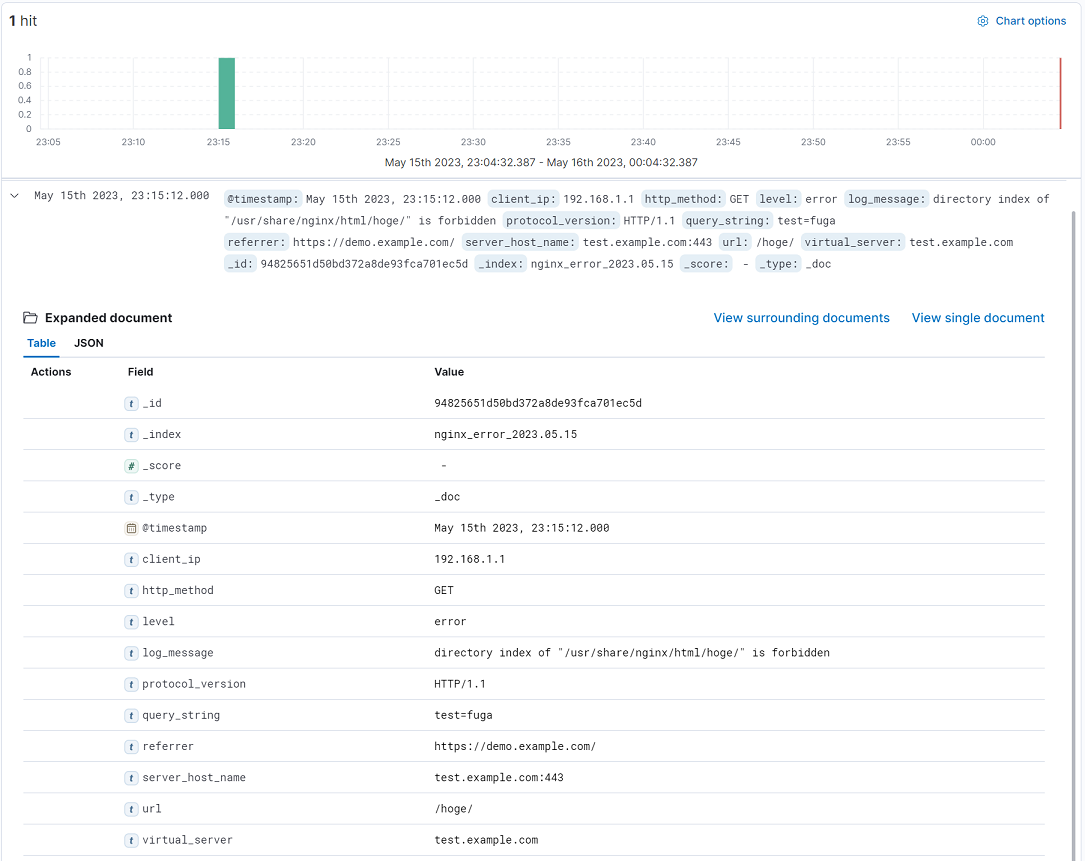
ログメッセージを構造化データに変換できたことでElasticsearchのインデックスフィールドで登録できているため、前述の例にあった特定のIPアドレスをKibanaの標準的なフィルタ機能で抽出できます。
nginxエラーログの構造化データ変換の説明
では、実際にnginxエラーログメッセージを構造化データに変換するための、FilebeatとLogstashについて具体的な設定について説明します。
Filebeatの設定について
最初にFilebeatの設定についてです。
「え?単純にエラーログファイルパスと転送先にLogstashのアドレスの設定をするだけではないの?」って思う方もいらっしゃるかも知れませんが、一点、重要な設定があります。
nginxのコードを読んでも中々気づきにくい事で、実は、nginxのエラーログメッセージ部分は複数行に跨って出力される場合があります。(Grok定義をつくるにあたり実際のエラーログを解析していて気づきました)
そのため、Logstash側にエラーログメッセージの内容を転送する際には、その複数行に跨ったデータを1つのログデータとして制御する必要があります。
Filebeatには複数行のテキストデータを制御するための機能が準備されていて、公式ドキュメントの「Manage multiline messages」に詳細が説明されています。今回は「Consecutive lines that don’t match the pattern are appended to the previous line that does match.」と書かれた設定パターンを利用します。
具体的な設定は以下の通りです。
# nginxのエラーログの先頭「(TIMESTAMP)」をパターンとして、それに該当しない場合は、前回のテキストデータに追加する指定。 multiline.type: pattern multiline.pattern: ^\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2} \[ multiline.negate: true multiline.match: after
この設定をFilebeatに定義することで、複数行に跨るエラーログデータも一塊でLogstashに転送できます。
Logstashの設定について
続いてLogstashの設定についてです。(今回はHTTP通信のエラーログに限定します。)
まず、以下に作成したGrok正規表現を記します。(※全てのパターンを網羅していない可能性がありますが、概ねこの正規表現でマッチします。)
^(?<log_timestamp>%{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}) \[%{LOGLEVEL:level}\] (%{INT:pid}#%{INT:tid}: \*%{INT:connection_id}) %{DATA:log_message_request}(?:, client: %{IP:client_ip})(?:, server: (?<virtual_server>[a-zA-Z0-9._-]+))(?:, request: \"(?:(?<http_method>[a-zA-Z]+) )?%{DATA:path_query}(?: (?<protocol>[a-zA-Z]+)\/%{BASE10NUM:version})?\")(?:, upstream: \"%{DATA:upstream}\")?(?:, host: \"%{DATA:server_host_name}\")?(?:, referrer: \"%{DATA:referrer}\")?$
上記の正規表現について、幾つかポイントを解説します。
- 「client: 」は、クライアントIPが出力されます。
- 「server: 」は、nginxのserverディレクティブのserver_nameが出力されます。本件では、ドメイン名か下記のnginxのdefault_serverのserver_name「_」がログメッセージに出力されることでのマッチ条件にしています。
server {
listen 443 ssl default_server;
# catch-all server 指定
server_name _;
}
- 「request: 」は、HTTPリクエストの先頭行が出力されます。ポイントは、nginxエラー文の「client sent invalid method while reading client request line」に該当するリクエストパターンを考慮したマッチ条件にしています。(具体的なパターンは割愛します)
- 「upstream: 」は、nginxをリバースプロキシとして利用した際のupstreamのアドレスが出力されます。通常のWebサーバ用途では出力されることは無いことのマッチ条件にしています。
- 「host: 」はHTTP Host header、「referrer:」はHTTP referer headerがそれぞれ出力されますが、HTTPリクエスト上に存在しない場合があるためのマッチ条件にしています。
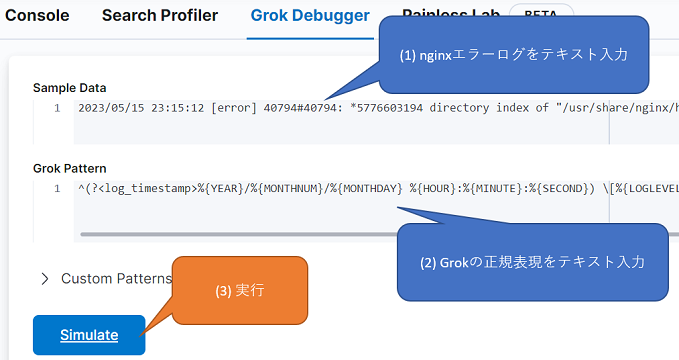
では、実際に、上記Grok定義で正常にマッチ出来ることを確認してみます。
一番簡単な方法として、Kibanaには、Grokを簡単にデバッグするために「Grok Debugger」というツールが用意されています。元々はX-Packの一機能のようでしたが、現在では無償で利用できます。
こちらで、以下の入力後にSimulateボタンをクリックして実行します。
正常に解析出来た場合、「Structured Data」の枠にマッチ後の構造化データが表示されます。(※本記事の最初に記したエラーログデータのイメージです)
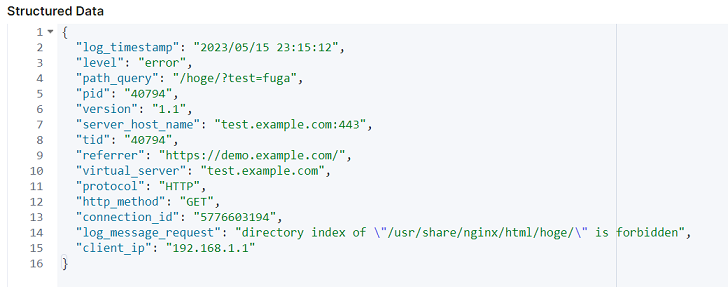
後は、実際にElasticsearchにインポートする際のインデックス形式に合わせるよう、Logstashの各種フォルターを用いて形成していきます。
例えば、この段階でリクエストパス(path_query)はパスとクエリ部分が「?」文字で結合された状態ですが、これをパスとクエリでそれぞれ分解したデータで登録したい場合は、Ruby filter pluginを補正します。(※正規表現で直接分解した値をキャプチャすることも可能だとおもいますが、メンテナンス性や可読性等を優先して今回はそのままのデータでキャプチャしています)
ruby {
code => '
# path_query->url,query_stringに分離
if event.get("path_query").nil?
# path_query自体が無い場合の例。
event.set("url", "-")
event.set("query_string", "-")
else
# 「?」で分割して、url,query_stringのそれぞれにセット。
arrayTemp = event.get("path_query").split("?", 2)
event.set("url", arrayTemp[0])
event.set("query_string", (arrayTemp.length < 2 ? "-" : arrayTemp[1]))
end
'
}
通常のケースについては上記のGrok定義で概ね対応できますが、もちろんマッチしないケースもあります。
例えば、nginxのエラーログのメッセージ上限サイズは「2048」である(参考)ため、全体のメッセージ文で「2048」サイズを超えた部分をカットした内容でエラーログに出力されます。このケースに上記のGrok定義ではマッチしないため、別途、今回のような例外対応するためのGrok定義を準備します。
^(?<log_timestamp>%{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}) \[%{LOGLEVEL:level}\] (%{INT:pid}#%{INT:tid:}: \*%{INT:connection_id}) %{DATA:log_message_request}(?:, client: %{IP:client_ip})(?:, server: (?<virtual_server>[a-zA-Z0-9._-]+))(?:, request: \"(?:(?<http_method>[a-zA-Z]+) )?%{DATA:path_query})$
最後に、上記の2パターンにも合致しない場合の、エラーログ取込漏れ(_grokparsefailure)を防止するための定義も準備します。
こちらは、nginxエラーログ標準のGrok定義です。
^(?<log_timestamp>%{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}) \[%{WORD:level}\] (%{NUMBER:pid:int}#%{NUMBER:tid:int}: \*%{NUMBER:connection_id:int}) %{YDATA:log_message_basic}$
通常時だと、例えば、
2020/03/15 05:01:20 [info] 26358#26358: *5749037605 client XXX.XXX.XXX.XXX closed keepalive connection
のようなログが該当します。
今回の場合、以上の3パターンのGrok定義を、LogstashのGrok filter pluginのmatchで指定します。(優先度の高い定義を先に宣言します)
grok {
match => {
"message" => [
"^(?<log_timestamp>%{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}) \[%{LOGLEVEL:level}\] (%{INT:pid}#%{INT:tid}: \*%{INT:connection_id}) %{DATA:log_message_request}(?:, client: %{IP:client_ip})(?:, server: (?<virtual_server>[a-zA-Z0-9._-]+))(?:, request: \"(?:(?<http_method>[a-zA-Z]+) )?%{DATA:path_query}(?: (?<protocol>[a-zA-Z]+)\/%{BASE10NUM:version})?\")(?:, upstream: \"%{DATA:upstream}\")?(?:, host: \"%{DATA:server_host_name}\")?(?:, referrer: \"%{DATA:referrer}\")?$",
"^(?<log_timestamp>%{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}) \[%{LOGLEVEL:level}\] (%{INT:pid}#%{INT:tid}: \*%{INT:connection_id}) %{DATA:log_message_request}(?:, client: %{IP:client_ip})(?:, server: (?<virtual_server>[a-zA-Z0-9._-]+))(?:, request: \"(?:(?<http_method>[a-zA-Z]+) )?%{DATA:path_query})$",
"^(?<log_timestamp>%{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}) \[%{LOGLEVEL:level}\] (%{INT:pid}#%{INT:tid}: \*%{INT:connection_id}) %{DATA:log_message_basic}$"
]
}
}
これにより、nginxエラーログを構造化することが出来ました。後は、Logstash内でElasticsearchのインポート先のインデックスの形式に組み換えを行い登録することで、Kibana上でエラーログの構造化データの検索が出来るようになります。(実際のElasticsearchインデックスは各実行環境に応じて定義することがよいとおもいます。)
この結果、SREチーム内でもnginxのエラーログの解析が誰でも簡単に行うことが出来るようになりましたので、問題解決でき、運用改善が出来ました。
さいごに
今回は、nginxの非構造化なエラーログデータを構造化したデータをElasticsearchに登録して、運用改善を行った話をさせていただきました。最後まで読んで頂きありがとうございました。この内容が何かのお役立てになればうれしいです。
今回はnginxとElastic製品をつかった運用改善ということで書きましたが、実際にSREチームでは関わるOS・ミドルウェア・プラットフォームも多岐に渡ります。もし、価格.comといった大規模サービスを通じて様々なアーキテクチャへの関わりにご興味をお持ちになりましたら、是非、以下のページをご覧頂ければ幸いです。

【補足】今回の環境について
2023年3月末時点の、以下の製品・バージョンで確認しています。
| 製品 | バージョン |
|---|---|
| nginx | 1.20.0 |
| Filebeat | 7.8.1 |
| Logstash | 7.17.3 |
| Elasticsearch | 7.17.3 |
| Kibana | 7.17.3 |